HPC with Step Functions
Building your own compute cluster is hard, so let's just use lambda functions instead.

Let's have a look at what we're deploying with this project. For this project I needed to evaluate a number of large equations, I then needed to sum all of the results together. You can have a look at the previous article to get the details about what this is calculating but to quickly get you up to speed we're calculating the total number of valid S3 key values that are valid unicode character combinations. The architecture diagram below shows how this project will compute the result.
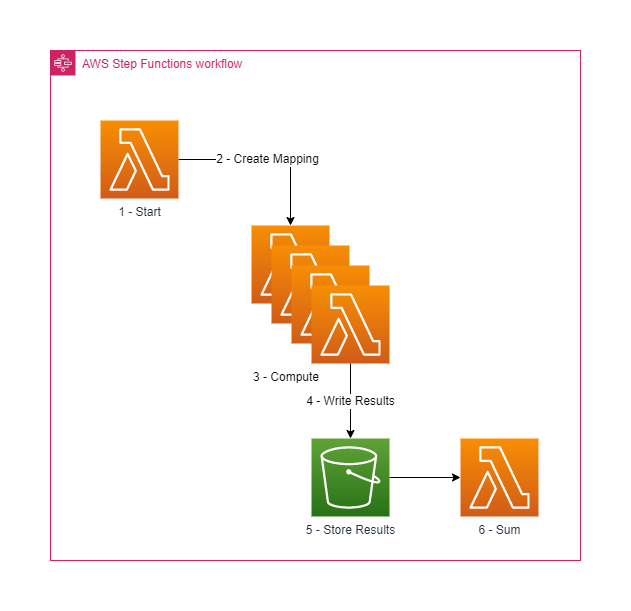
As you can see the design of what we're going to build is very simple. There are three lambda functions which make up the compute component of our cluster.
- Start function which creates the inputs for the number of jobs we want to run.
- Compute function that will run the calculation that needs to be computed for the workload. This runs in parallel across a distributed map to compute the answer.
- Sum function will take the results from the compute functions and sum the values to calculate the final answer.
lib directory will be a *-stack.ts file. Here is where we will
define new constructs for our stack. To start with lets create constructs for
our three functions.PythonFunction is a special construct that will bundle python lambda functions
as part of the CDK deployment. The code for each function is located in the
following files. You can see what they're doing below.size and
returns an array of length size. This will be used in the compute function to
specify how large the map will be.The compute function is the main part of this pattern. This is where all the calculations for the process are done in parallel. You can modify what this lambda does to change the type of calculation done.
The last part of the step function is to sum all the results from the compute step. Since this step function is based on a distributed map the results are stored in an S3 bucket (more on this later). To read the results we just download the file and then return the sum of the results.
DistributedMap is defined in a stateJson object
instead of a strictly typed object.With the map created we can now create the step function and build our state machine definition. The start and sum functions must be wrapped in a step function stage which can be added to the state machine defintion.
The last part is to add the proper permissions, the custom distributed map doesn't add the required permissions to the state machine automatically so we need to define these ourselves as well as permissions necessary for the step function to access the results bucket.
With our stack defined we can now deploy the function into our AWS environment.
Once the stack is finished deploying we can go ahead and run the step function. You can either run the step function from the console or via the command line using the following command.
We can view the progress of the invoked function inside the AWS console.

1024 the output should be:Which is a pretty big number. With each function only computing an individual size the total time to invoke took 10 minutes, this was mostly due to the unoptimised python code I have written but if you choose to refactor the example I have here you can get vastly faster speeds.
So there you have it, a simple pattern to run HPC workloads using step functions. I've used this template problem to do lots of different things like copy a large amount of files from S3 into EFS. There are plenty of use cases for this design so feel free to tweet (or toot) if you end up using this!