Building a Contact Tracing Platform
Learn how to automate and build an application to trace exposures using Amazon's Cloud Development Kit (CDK)

TLDR: I made a contact tracing app that you can access here on vercel.
§Introduction
Infrastructure as code is the best way to manage the deployment and maintenance of applications as well as the hardware required to operate them. Writing configurations for applications as code allows for easy, repeatable, and identical deployments across multiple environments. In this article I'm going to describe how to use the AWS Cloud Development Kit (CDK) to create an application and deploy it to an AWS environment.
AWS CDK is an open source framework for defining cloud application resources - including compute, storage, and security resources. It's avaliable in a number of languages including TypeScript, Golang, .Net, and Java. The advantage to using CDK is that you can develop the resources for your application in a language your buisness already uses so developers don't need to learn a new language to deploy and configure an application.
To show how easy it is to create an application with CDK I'g going to make something topical. At the time of writing Melbourne is under it's 6th covid related lockdown, one of the reasons given for the lockdown was that contact tracing personnel were inundated with exposure sites, which needed to be notified, which then needed their staff and customers to be isolated and tested, while their whereabouts traced. This type of problem can be automated, so I figured, why don't I try to build a contact tracing app?
If you want to see the entire project or a particular snippet of the code I've written for this demo you can find it on github.
§Architecture
§Backend
To start with, here is a basic architecture diagram of what the backend services look like.

The backend architecture for this application is quite simple, the system is based off of a serverless architecture so its cost is proportional to the amount of use it receives. The API which will handle the contact tracing is managed through Amazon AppSync - a managed graphql service. GraphQL is a language and specification for data query and manipulation used most commonly with APIs. Appsync is a great service because it gives front-end developers the ability to query multiple databases, microservices, and APIs with a single endpoint. Since there's only one endpoint it's really easy to update the API in realtime by just adding more data sources. To create an API all you need to do is define a schema and where to fetch the data from and you're mostly done. There are a few more steps if you want to define authentication and more complicated data sources but for the most part it's plug and play.
time, user_id, and location_id. DynamoDB queries need a partition key to
search upon (a primary key analogue) and can be refined using a sort key, in
the application I'm using the user_id and location_id as partition keys
while the date will be the sort key. DynamoDB tables support a single partition
key, to use multiple partition keys in DynamoDB you need to use a
GlobalSecondaryIndex.Authentication is vital for real world services. Having the ability to verify users who will access sensitive data (checkin data is Personal Identifying Information - PII) is absolutely needed. AppSync supports multiple simultaneous authentication methods - including API keys, IAM user signatures, Amazon Cognito, and external OpenID providers. For this demo I'm going to use Amazon Cognito which is a managed authentication service that can store thousands of user credentials securly in the cloud.
lib directory, the functions
directory contains all the API code and the graphql directory contains the
schemas.What is CDK?
The AWS CDK is a framework that can be used to define and organise resources on the AWS cloud. Any project in CDK is setup using "stacks" which are individual deployments that resources are grouped by. In actual fact CDK stacks are synthesized into Amazon CloudFormation templates and deployed using CloudFormation.
CDK is avaliable in a bunch of different languages but for this demo I'm going to use TypeScript to define my CDK stack.
I'm using CDK v2 is this demo because it's pretty close to being released soon. CDK v2 has a bunch of improvements over the first version which you can read about on the aws blog but for this demo it won't matter too much which version you use.
The first thing to do is install the CDK CLI, now if you're using another language like Go or Java the installation will be a bit different but there are instructions for each language on the CDK website.
After this you can create a new CDK project in an empty directory based off the app template as shown below.
After this you should have a blank CDK project, woo! To verify you should have a directory layout similar to the output below.
Defining the Schema
GraphQL is first and foremost a query language. It's used to describe the data in an API, ask for specific data, and return predicatable results. All queries to a graphql API are sent to one http endpoint which supports POST requests. The data sent in the post request defines the query/mutation and what information to return.
scalars.graphql
file. This is used for linting purposes during development, the graphql
specification defines a few specific data types that all engines must support
(things like String and Float) but any engine implementation can have extra
built-in types, in fact you can specify your own in the schema. AppSync has
several built in types that we're going to use so, to help tools like vscode and
intellij understand these new types we can define another schema file that is in
the same directory as our main schema that won't get used by the CDK stack but
will be used by any tools that scan the directory.Writing the Functions
The backbone of an AppSync API are the data sources. The data sources map to a query or mutation object and tell AppSync where to get or set the data for the operation. At the time of writing there are 6 different data sources: DynamoDB, Elasticsearch, Lambda, RDS, HTTP, and None (this is just an empty placeholder).
This API uses two different data sources. For simple key retrivals the API has a DynamoDB resolver, this data source can query the table directly using a mapping template and return the results. There are a few advantages to doing this, the main one is that you don't need to write an extra lambda function in another language to query the database.
The other resolver used is the lambda provider. AppSync can use Amazon Lambda functions as a data source provider, using lambda to run functions allows your API to run any arbitary code needed to get a result for the API. Also since lambda functions can now run docker images there isn't really any function that your API can't do.
go mod.The manifest file is used by the Go toolchain to track and download dependencies for a program, it's also used in the build steps to validate the structure and version of Go the program is compatible with. After making the manifest file you can create a Go file in any sub-directory which is a great way to organise the code your going to write. Below is an example of how I've laid out the structure of the contact tracing API functions.
A Quick Note on CDK V2 and Golang Lambda Functions
Common
utilities.go file
has two public methods: GetLocationVisitors and GetUserLocationHistory. In
the snippet below I've only added the code required for GetLocationVisitors as
an example of how to build a function that can access Dynamo.CheckIn struct is using dynamodbav tags to
define the relationship between struct properties and DynamoDB properties. Tags
are using ing Golang to provide additional context to properties in structs,
they're most commonly used for (un)marshalling JSON and XML data with structs
without the need for custom code to handle the process.dax. In this app I'm using DynamoDB
Accelerator (DAX) to cache the results of queries and speed up the API response
time. I'll go into more details about setting up and configuring DAX later but
for the time being wherever you see DAX code in the API you should know that you
can also use DynamoDB clients as well.NewQueryPaginator will handle the work of collecting multiple pages of
data and is a drop in replacement for the standard Query method.Trace Exposure Function
import statement. The
structure of the code is fairly strightforward so I won't go into too much
detail; the flowchart below describes how the algorithm works.
Building the Stack
lib directory there should be a file similar to
contact-tracing-stack.ts this file contains the stack and resources that will
be added to the app. Inside the file there should be a single class which will
be the stack definiton.VPC
DynamoDB Table
There are two resources that need to be created for the Dynamo database. The first is the table itself, and the second is a global secondary index. The Dynamo table will allow querying using a single partition key and optional sort key for this table; the location ID will be the partition key and the check in date will be the sort key. This will mean that queries the table based by location will be trivial, but it won't be possible to run a query based on the user. The way to solve this using Dynamo is to create another index. There are two types of secondary indexes in Dynamo, Global Secondary Indexes allow for another partition key while Local Secondary Indexes provide another sort key. Since we're going to be searching for a user and sorting the results based on the check in date we only need a Global Secondary Index.
Using Dynamo Dax
Over the course of this project I found that some of the larger requests were taking up to 16 seconds to run. In terms of making a responsive website that's incredibly slow. As I investigated the issue I found that over 99% of the execution time was being used witing for DynamoDB queries. Now like I said at the top of this article Dynamo is really fast, queries usually take less than 5ms to run, but when you're creating a contact tracer that has to cross reference thousands, potentially millions of people and locations those 5ms add up. You can see the latency in, each segment represents a query operation; as you can see the number of queries rapidly increases.
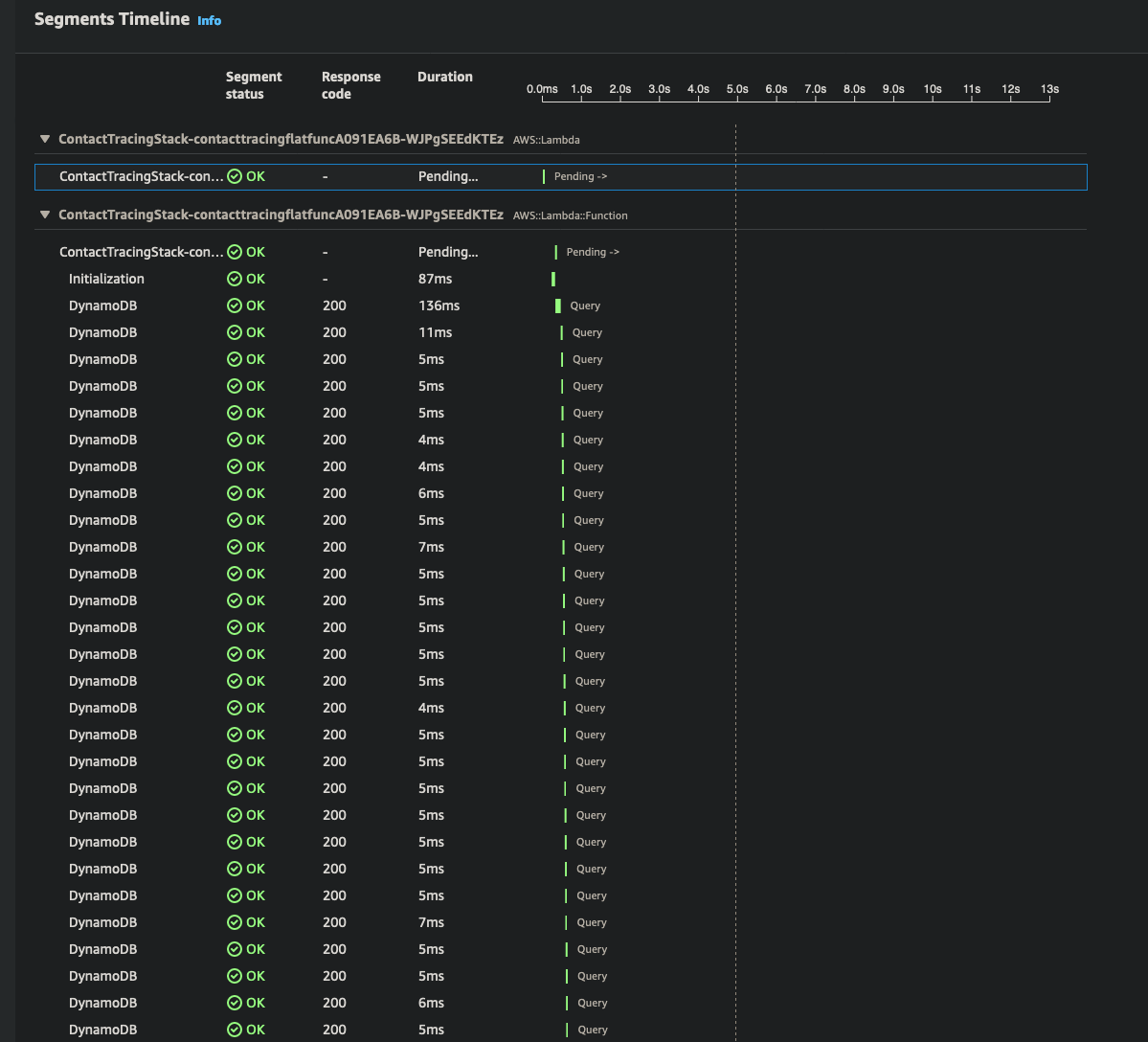
To speed up these request I decided to use DynamoDB Accellerator (DAX) to cache the results of any Dynamo queries. DAX is an in-memory cache that can deliver up to a 10 times performance improvement for DynamoDB queries. It does this by creating a cluster in your VPC that can communicate with any application connected in that VPC. DAX is a drop in replacement for DynamoDB - meaning that if you write code to work with DynamoDB all you need to do is replace the DynamoDB client with the DAX client and it will work right away, there's no need to change any of the application logic to support DAX API calls.

My intial thought was that most of the queries that would be executed would be repeats of previous queries - this assumption however, was wrong.
<Rant>aws-sdk-v2 has been in active public development for
a few years and was classified generally avaliable in January of thos year.Now here in lies the problem, because v2 of the Golang SDK is a complete rewrite, this library is incompatible with the new SDK version. Now you'd think that there would be support for the new SDK considering both of these repos are official AWS repositories but alas.
</Rant>aws-sdk-v2 code) you need to add this snippet to the bottom of your go.mod
file to let the toolkit know that you want to use a fork of the original
repository.After all this work I tested the API calls and success! Kind of; well the first request is still slow but any identical subsequent requests are much faster (less than 1ms). The only problem with this is that most of the requests are not going to be identical so the speedup isn't really worth the effort. I've documented what I've done for the sake of completeness but I don't recommend using DAX for a problem like this.
Cognito User Pool and Client
Next to set up Cognito; there are two resources that need to be created. The first is the Cognito User Pool, this resouce will hold all the information about users who aceess the API - mainly their email and password. The second component is the Cognito App Client, this resource is used as an endpoint for web services to talk to Cognito, it specifies what authentication methods are valid.
AppSync API Schema
Now with the dependencies out of the way we can now create the AppSync API. The first part is to define a new AppSync API resource and the schema the resource will use.
This will create an AppSync API that will use the attached schema we created before. But at the moment none of the data values in the schema are connected to a resolver. To do this we'll need to create some data sources and resolvers.
AppSync Data Sources and Resolvers
The Data Sources and Resolvers are a critical piece of the API infrastructure, they connect AppSync to all the storage and compute resources behind your API so making sure they're correctly defined is crucial.
The first Data Source we're going to make is for a direct DynamoDB connection. To make this we're going to give AppSync full access to our DynamoDB to read and write to our table. We're then going to point AppSync to the DynamoDB table we created before.
get_user_location_history and get_location_attendees API queries
which will be used by the API to get results for specifics users and locations
on the pages https://ct.vercel.app/location
and https://ct.vercel.app. Direct DynamoDB resolvers
are useful when you don't need to use much buisness logic to return API data.
The resolver only needs a mapping template that can convert the input into a
DynamoDB transaction. The result is then converted into a JSON compatible string
and returned to AppSync.PutItem operation.get_user_location_history, get_location_attendees, and
check_in are connected to a data source. The final call we'll look at is
trace_exposure_flat. First we're going to create a Golang function using the
plugin that I mentioned in
A Quick Note on CDK V2 and Golang Lambda Functions
and we're going to set some environment variable from resources we've already
created and create some security policies to grant access to resources.Next we're going to create a service role that AppSync can use to invoke the Lambda function, as well as create a Lambda Data Source.
After we've created a data source we're going to connect it to a resolver like we did before.
There you have it, now the lambda function we wrote before is connected to AppSync and can be used for API calls. All that's left to do is deploy the stack.
Deploying with CDK
Deploying with CDK is easy to do, there is a single command that will generate the CloudFormation template and deploy it to the configured environment.
One thing to mention here - A useful feature of CDK is the ability to use CloudFormation Outputs to print attributes that are useful. For example the API URL, Userpool Id, and AppClient Id are all values needed by the frontend which can be hard coded into the environment.
§Frontend
create-next-app tool which is pretty similar to create-react-app if you're
farmiliar with that.After running the setup command you should have a directory something like this.
npm run dev will start up
the development server and you should see a starting page. We're not going to be
using this page or the API setup by next so you can delete the pages/
directory. We're going to make two files in the src/pages directory -
_app.tsx and index.tsx. They should look something like this.npm run dev next will warn you that you
don't have typescript or the right types installed. To fix this run the
following install script:Hello, World!
page. Now we can set up the components of the app.Setting up Authentication
When we set up the backend we created a Cognito userpool and client and connected our userpool to appsync. We're now going to use our client to get an authentication token that will work with AppSync, the flow should work something like this:
- User loads the website.
- The website checks to see if the user is logged in.
- If yes go to step 5.
- Direct user to login or signup.
- When user logged in ask Cognito for an authorization token to send with API requests.
- Cognito returns a token that can be used.
These steps are pretty straight forward but can be very tricky to do correctly. Fortunately there is a prebuilt library for Cognito authentication that we can use in the AWS Amplify package.
Auth object to connect to
our Cognito client, for this we need the ID of the user pool and the client
which we had exported from our stack before. Let's save them for the time being
and add them to the code as environment variables.Connecting Authenticator to React
To make sure that the page shown to the user is always authenticated I've made a simple hook to return the authentication state to the page. Be aware this is a simple example of what should really be built into a React provider but it's fine for example purposes.
Setting up Apollo
Now that our authentication is set up we can contact the AppSync API and run queries/mutations.
Apollo is a GraphQL implementation that can be used to generate and create an API similar to AppSync. For our use however, we're going to be using the open source client library that Apollo provides to execute queries against our endpoint. First thing we need to do is install Apollo.
authLink
context.apolloClient file creates a React hook that can be used by next as a
provider - a type of React component that provides a context. A Context
provides a way to pass data through the component tree without having to pass
props down manually at every level 3. Now we can wrap our app in the
<ApolloProvider> making our API avaliable to any React component in the tree.Now when we build the data components in our app we can automatically get data from our API.
Geting Data From the API to our Page
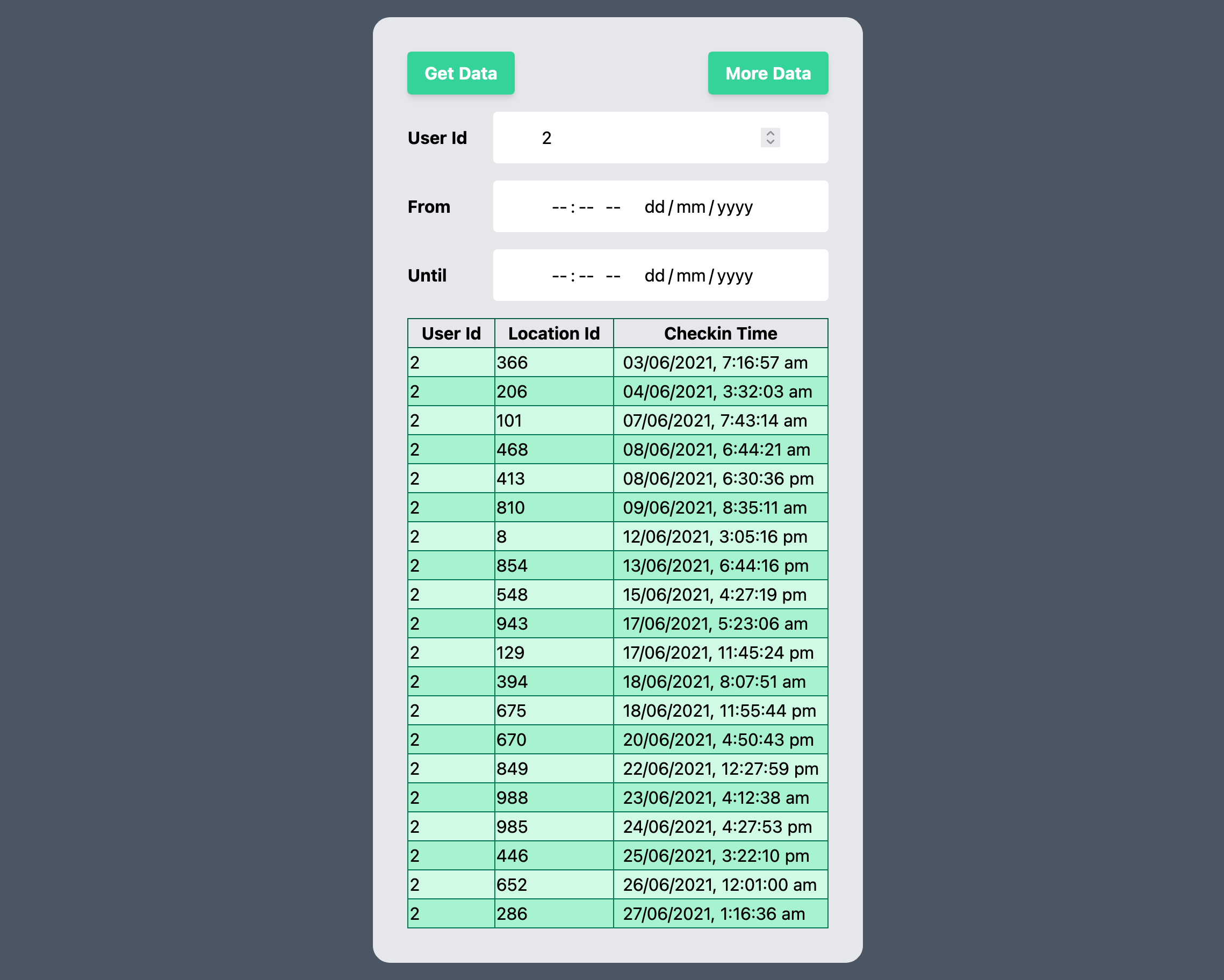
index.tsx page. We're going to make a simple
table display to show the data for a single user.get_user_location_history and save it in a file can we import from later.UserTable component
if the user is authenticated.UserTable component is where all the buisness logic is found, we're going
to use the useLazyQuery hook to get the data from our API when a user presses
a button on the page.Now when you reload the page you should see something like this.
Building D3 components
So now that we have the data avaliable to React we can now do something with it. Since the user is on a site to view contact tracing data they probably want to see the data requested. There are lots of different ways to view this data but I'm going to explain how I made two of the layouts on the site in this article otherwise this post would never get finsihed. We're going to make a Radial tree and a Force-Directed tree.
There are lot's of ways to display data on a website, the earliest and most mundane system is to simply use tables like we did before. But using tables to display data can often obscure the more intricate connections and details in the data. Having custom elements that can display the data in different ways to emphasise and highlight specific facts and connections is a mcuh more user focused approach.
To help with this we're going to be using a library called D3 - a JavaScript library for manipulating documents based on data. D3 allows you to bind arbitrary data to the Document Object Model (DOM), and then apply data-driven transformations to a document. This approach is incredibly powerful, allowing developers to build anything within the scope of the DOM APIs.
Another advantage of D3 is the large set of utility modules that come included; while building the different components we're going to use a fair few of them.
Radial Tree
The first component we're going to make is a radial tree, this is a type of tree that has all the nodes sorted and aligned around a central root node. It's really useful for understanding the depth of a tree and how sparse or dense it is.
To start off we're going to make an empty NextJS page which will render an svg component.
/radial-tree. Now
it's time to add our connection to the AppSync API using Apollo. The Apollo
client library for React manages both local and remote data with GraphQL.useLazyQuery React hook. This method will take the query string and variables
and send these to the server.First we'll define the query to execute. We can place this in a seperate file and export it into the component, this will be useful later as multiple components need to use the same query. Plus it's also tidier.
SearchBox which just creates a form
and validates the inputs using Formik, you can read more about it in the repo,
for the time being assume it's a form and the onSubmit function runs when the
form is submitted.So now when the user selects a date and user id the API will be called through the React layer and return data to the view. Now all that needs to be done is display it.
There are a lot of moving parts in modern React applications, let's just pause for a moment and understand what we're doing and what the tools and frameworks we're using are designed for.
Apollo is a framework for data and state management, it's designed to fetch data, keep it in sync with the server and relay changes, it's the Model in the MVC pattern.
The final part is the view, we have a list of data that needs to be displayed to the user after they make a query, as eluded before to display the data we're going to be using D3 which is a JavaScript library for creating interactive visualizations in the browser. It's essentially a way of generating shapes and charts using svg components and html cavases. But the way it does this is amazing, there are so many tools and helper functions to build scales, shapes, charts, lines, and colours that you can pretty much create anything you can think of.
The advantage to D3 is the ability to create anything, the disadvantage is you have the ability to create anything, there are no prebuilt components - you need to know what you want to make.
To begin with, we're going to create another React hook that is dependent on the size of the window, and the data. The hook is going to create an svg selection using D3 that we can use to manipluate and edit the contents of the svg page.
tree builder is exactly
what we need.Combining all of these constructor elements together and adding them to our hook gives the following code.
Great, so now we have the methods and structures in place to add data to the page, we're almost there. The last thing that needs to be done is to build the tree visually using svg elements. In a tree there are two seperate sections - verticies, and edges.
select tool we can create a group of svg path elements to
represent the tree edges, the co-ordinates in the canvas are calculated using
the tree builder so we only need to call the links method to pull the data
for each element.circle svg
elements and calling the descendants method to retrieve all the vertex data.The entire svg generation can be seen in the below snippet, there is some code that explains how the tree is wrapped into a circle as well.
After adding all these components if you refresh the page you should see something like the tree below.

If everything is working you can now generate a tree that shows the contacts and locations exposed to a person. But it's pretty hard to gleam any usable information from this tree at the moment. We can fix this by adding some contextual data using event listeners and add vertex and edge information to the tree when a particular element is hovered over.
Now when you hover over a part of the tree you should see a handy tooltip.

Force-Directed Tree
Another visual we can create is the force-directed tree - a visualization that uses a numerical integrator for simulating forces. This visualisation is really good at showing clusters and relative sizes of tree groups. The setup and implementation is identical to the radial tree we created before, the only difference is the D3 render hook. In it we're going to create a simulation object and link it to our tree structure.
radial-tree.tsx and replace
the hook with the code seen above you shoud see something like this.
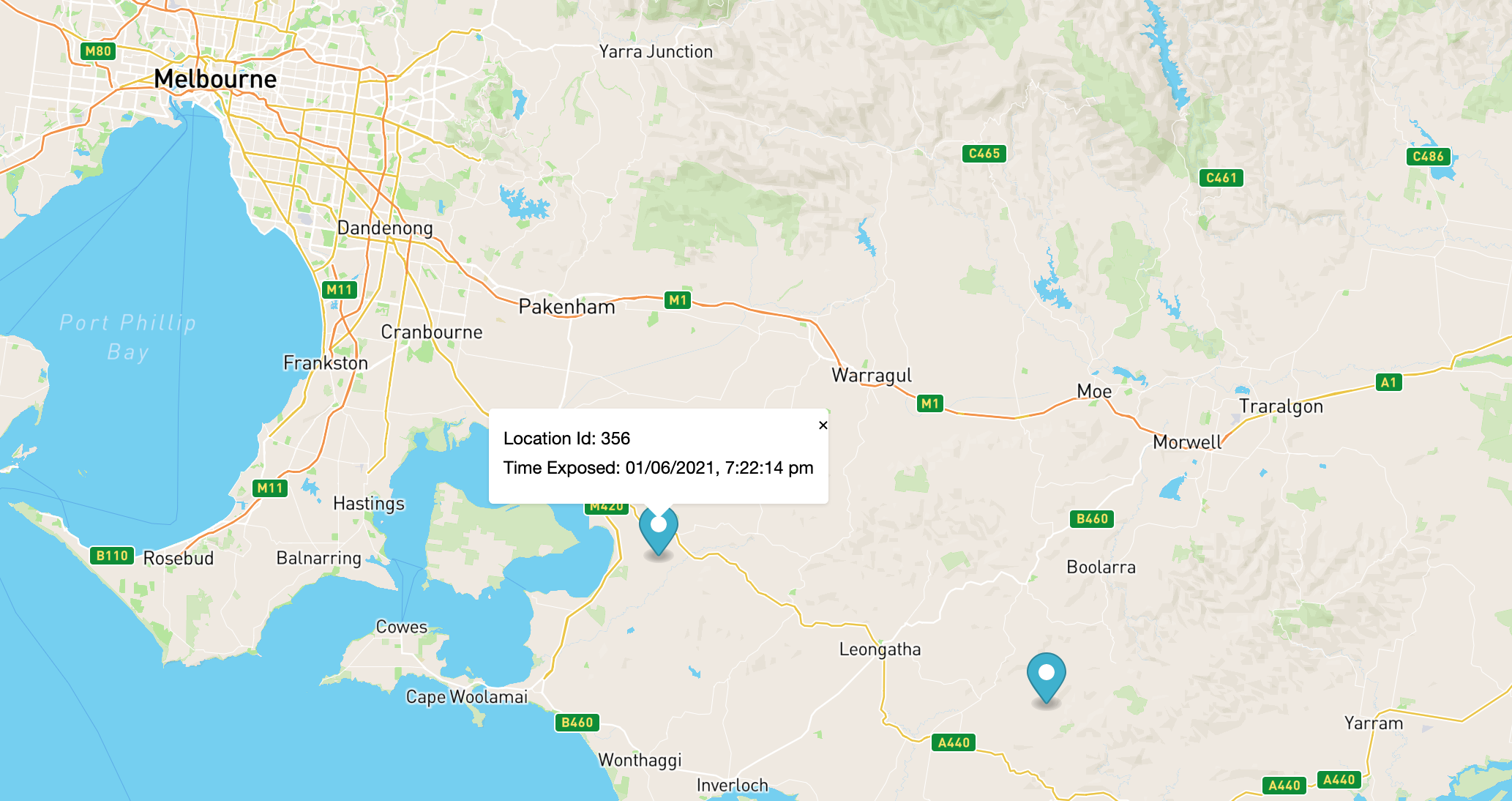
Mapping using MapBox
Visual components are great but sometimes you need to display data relative to the real world. Maps are the best way of displaying geographical data. In this component I'll show you how to overlay geographical data on a map.
map.tsx which will be our base. To
make the map we're going to use a library called
mapbox. Mapbox is a great service that provides high
resolution maps with their SDK.To set up the map we're going to import the JavaScript SDK and the map styles. We're also going to create a div which will be the map container.
useCallback hook to make a custom reference for our map
that can be updated when the page loads the SDK.When the map is initialised we can being displaying data using a react hook similar to how we displayed data in the D# components.
And there you have it! Now the map can load data and then display it on a page. If you refresh the page you should see something like this map below.
§Final Thoughts
If you've made it this far, well done! This article turned out a lot longer than I originally planned. I thought about splitting it into multiple articles but I think the flow of a single document is easier to understand and consume.
aws-sdk-v2 really slowed down my development. The D3 charts also took a long
time to make, but once they started to work it was okay to iterate and improve.§Footnotes
-
So there are multiple imports for CDK that you'll need depending on which resources you define. The main CDK import
aws-cdk-libcontains all the modules for individual services, to import specific services the best way is to alias the import like soaws_cognito as cognito. ↩ -
Maybe another project? ↩
-
The definition provided by the React docs. ↩
-
Okay so not quite. In the documentation it says "React isn’t an MVC framework. React is a library for building composable user interfaces." But in context to how React is used in this application it's essentially the controller. ↩
-
For more information about this little quirk of JavaScript take a look at the docs on MDN, actually since these components aren't modifying the data this clone isn't really needed, but it's still good practice to treat API data as immutable objects. ↩